Fairlearn: The secret to teaching your models to play fair

Microsoft just announced a new suite of tools around Responsible AI during the Microsoft Build conference. One of the tools that they announced is fairlearn. A new python package that will help you build fair models. In this article I’m going to show you that fairlearn is the secret sauce to building fair models.
In this article, we’ll cover the following topics:
- What is fairlearn, and why should I care?
- How do I check if my model is fair using fairlearn?
- How can I improve an unfair model using fairlearn?
Let’s get started by exploring what fairlearn is and why it’s an exciting tool to use for machine learning engineers and data scientists.
What is fairlearn, and why should I care?
Fairlearn is a new Python package developed by Microsoft. It implements several algorithms to detect and mitigate group fairness issues in machine learning models. Before we dive into what fairlearn offers, let’s first try to understand what model fairness means.
Why is being fair important?
When we train machine learning models, we want them to behave fairly. But despite our best efforts, we may harm people. There’s two ways in which we can talk about fairness: Fairness towards an individual, and fairness towards groups of people. Fairlearn aims to fix group fairness issues.
There’s a couple of ways in which a machine learning model could harm groups of people that fairlearn aims to solve:
- First, there’s the allocation harm: Denying access to products, services, or information for groups of people
- Second, there’s the quality of service harm: A group of people gets a lower quality service, product, or information. Even though they have access to the product, service, or information source.
Both problems are bad for business. For example, denying a credit card loan to a customer based on gender, ethnic background, or the location of the customer harms the customer and is illegal. There’s not going to be a lot of discussion about that. Now imagine, the same customer gets a credit card loan, but the machine learning model decides that the person should get a higher interest rate on their credit card loan than someone else. The person still gets a credit card, but we’re providing a lower quality of service. The higher interest rate looks good but it’s unfair to the customer.
A model that discriminates is forbidden by law. But we can’t really see that with the naked eye because of the complexity of machine learning models and the associated datasets.
And even if we don’t break the law, an unfair model is just bad for business. We’ll sooner or later lose customers because we’re using an unfair model.
How does fairlearn help?
Fairlearn offers a couple of tools that help you detect and mitigate unfairness in your models. There are two main features in the fairlearn package:
- Assessing fairness: Fairlearn contains a
FairlearnDashboardcomponent and a set of metrics that help you measure the fairness of your model. - Mitigating unfairness: Alongside the metrics, and dashboard, there’s a set of algorithms in
fairlearnto help mitigate unfair behavior in models. You can, for example, use a postprocessing algorithm to improve existing models. But there are also a couple of algorithms that help you improve the model during training.
Let’s look at a couple of the components in the fairlearn package to discover how they help you detect and mitigate unfair behavior.
How do I use fairlearn to validate my model?
To understand how fair your model is, we need some way to measure fairness and visualize the results. This is where the fair learning dashboard comes in.
As an example, we’re going to look at a model that predicts whether a customer is going to default their next credit card payment. The model is trained using historical data and some general properties of the customer.
The output of the model is 1 in case someone is likely to default their next credit card payment. The output is 0 in case someone is likely to pay on time.
We can use this model to score a credit card application. If the model predicts 0 we grand the customer a credit card; Otherwise we deny the credit card application.
Now, let’s take a look at how this model behaves when we assess its fairness.
The fairlearn package contains a component called FairlearnDashboard. It’s a widget that we can use within a Python notebook which measures and visualizes two metrics for our model:
- Metric disparity: a measure that we can use to see what the difference in performance is between different groups of users for our model.
- Prediction disparity: a measure that shows the difference of true positives between groups for binary classification models. For regression models it shows the difference in distribution of predicted outputs for different groups.
To use the fair learning dashboard, we need to write a few lines of Python.
FairlearnDashboard(
sensitive_features=df_test['SEX'],
sensitive_feature_names=['Gender'],
y_true=y_test,
y_pred=classifier.predict(x_test))This code performs the following steps:
- First, we collect a set of predictions using a test dataset.
- Next, we collect a set of sensitive features, these identify the groups of users.
- Then, we collect the names for the sensitive features.
- Finally, we call the
FairlearnDashboardconstructor and feed it the data we collected.
The output of the code can be seen in the picture below.
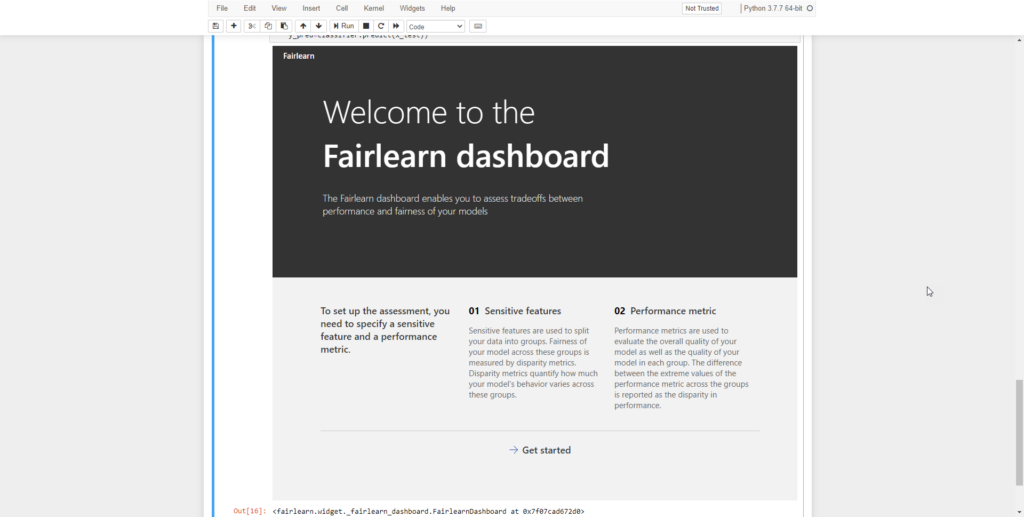
After executing the code, we’ll get a dashboard allowing us to select a sensitive feature that we want to explore.
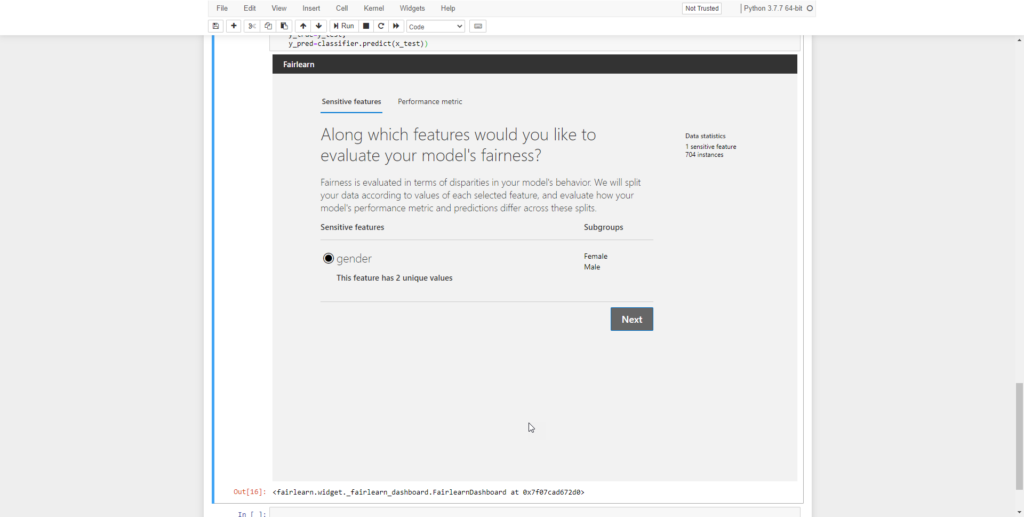
Once we’ve selected a sensitive feature and clicked next, we can choose a metric to explore for the sensitive feature.
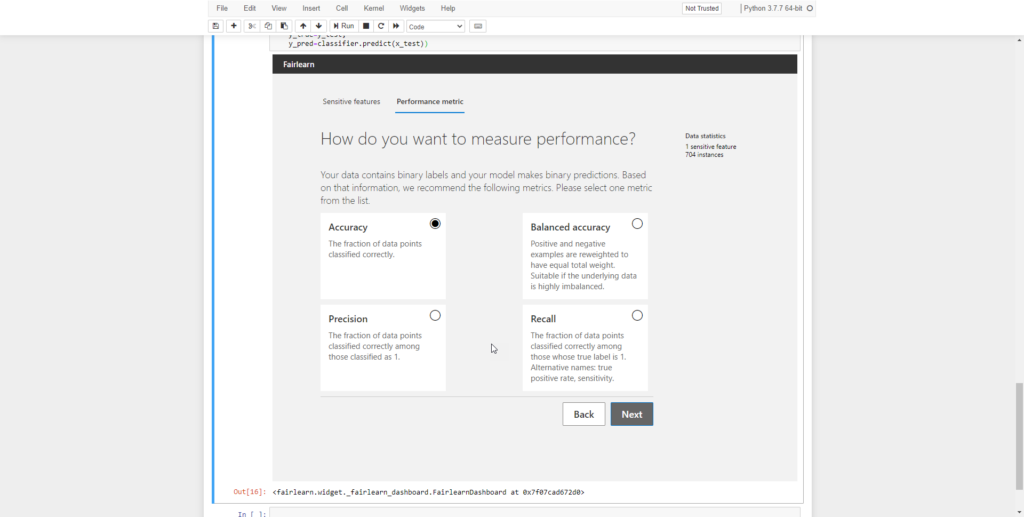
Finally, when we click next again, we get a dashboard that shows the results.
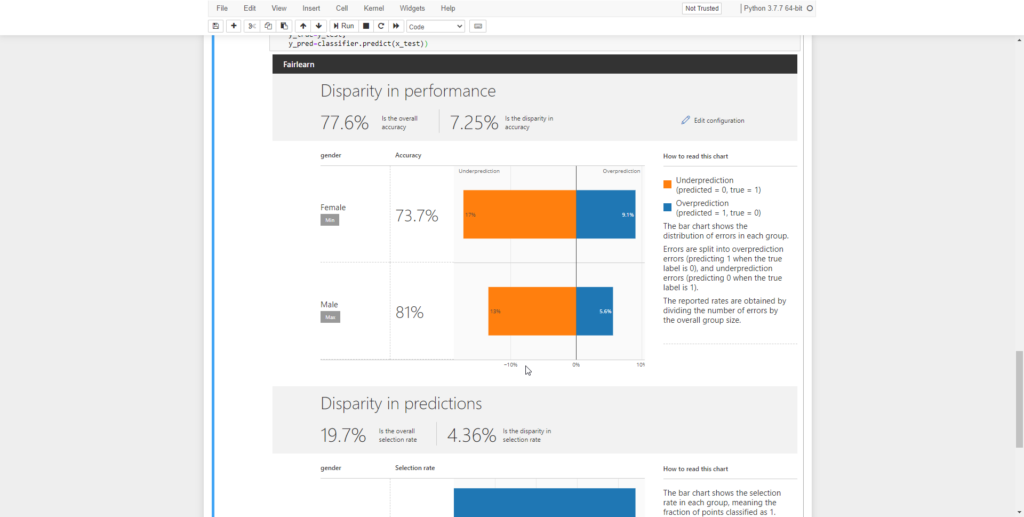
The top half of the dashboard shows the performance disparity. From the chart you’ll notice that the performance of the model is worse for male users.
There’s another interesting detail that we have to look at. Check out the under prediction for female customers (The orange bar for the value 2).
When we were to use this model, it would be more likely for a female customer to get a credit card. And this isn’t so much based on their income or past behavior. It’s because of a gender bias in our model.
Now let’s take a look at the bottom half of the dashboard.

When we look at the bottom half of the dashboard, we can see the prediction disparity. In the case of the image above, it shows that there’s quite a large difference for male and female customers. It’s far more likely for a male customer to get denied a credit card, because the model predicts that the customer is going to default their next payment.
From the dashboard we can conclude that the model is doing worse for male customers than for female customers.
But how are we going to fix that? Let’s look at some options for fixing your model.
How can I use fairlearn to improve an unfair model?
The fairlearn package contains several algorithms that help solve unfairness in models without changing the data that we used to train the model.
There are two strategies that we can apply to solve unfairness with fairlearn:
- For existing models, we can mitigate unfairness using postprocessing.
- For new models, we can use reduction algorithms to improve fairness.
For this post we’re going to focus on using post-processing to improve an existing model.
Using the ThresholdOptimizer algorithm to improve an existing model
When we have a trained model, we can use a postprocessing component called the ThresholdOptimizer to equalize the odds between different groups of users of our model. In a sense, we’re giving each group an equal playing field, so the outcome of the model no longer depends on sensitive attributes like age, ethnicity, etc.
The TresholdOptimizer is based on a paper called “Equality of Opportunity in Supervised learning”. It tries to correct the model so that it no longer discriminates against specific groups of users, based on a set of sensitive features.
To use the TresholdOptimizer, we need to have one or more features in our data that we identify as sensitive. For example, this could be age, gender, ethnicity, or similar.
Let’s apply the TresholdOptimizer to an existing model:
optimizer = ThresholdOptimizer(\n estimator=classifier, \n constraints='demographic_parity')\n \noptimizer.fit(x_train, y_train, sensitive_features=df_train['gender'])Training the TresholdOptimizer.
This code performs the following steps:
- First, we create the TresholdOptimizer for the model.
- Then, we train the optimizer using the original training dataset including the sensitive features for the training dataset. We’ll be using ‘equalized_odds’ as the constraint.
After we’ve trained the optimizer, we can use it instead of the normal model to make predictions. It has the same interface as a regular scikit-learn model meaning, we can call predict and transform on it to make predictions:
optimizer.predict(x_test, y_test, sensitive_features=df_test['gender'])Making a prediction using the TresholdOptimizer.
Note, that we’ve used a scikit-learn model as the input for the ThresholdOptimizer. The algorithm used by the TresholdOptimizer is a blackbox solution. This means that we can apply it to several types of models. Right now, binary classification models and regression models are supported. If they have a fit and predict method.
Deep learning-based models often aren’t based on the estimator structure that scikit-learn has. You can still use the TresholdOptimizer by wrapping your deep learning model in a class that derives from sklearn.base.BaseEstimator.
The TresholdOptimizer is not a magic component that will fix all our problems. It will only reduce the fairness problems in our model. Sometimes not by a lot and sometimes it does help a great deal.
Conclusion
In this post we’ve talked about several techniques that fairlearn provides for improving your model’s fairness. We’ve looked at:
- Measuring fairness using the fairlearn dahboard widget.
- Improving fairness for trained models using
TresholdOptimizer - Training models with improved fairness using
GridSearch
If you’re interested in the code, it’s up on Github: https://github.com/wmeints/fairlearn-demo
Please leave a note on my twitter account (@willem_meints) if you have any questions!